Deploying Large Language Models Locally and Securing Sensitive Data
A guide to set up in-house Large Language Models, ensuring data privacy and tailored AI in SMBs and homelabs.
A step-by-step guide on deploying a locally-hosted Large Language Model (LLM) in small and midsized business (SMBs) or homelabs. Just a few years ago, operating LLMs in-house was not possible. Today, it’s a reality accessible to many, and this guide is here to demystify the process. Setting up a local LLM is very simple and straightforward.
Advantages of running LLMs locally:
- Confidentiality: Running an LLM locally means that all sensitive data stays within your control, on your own servers. This aspect is crucial for handling sensitive information as it markedly reduces the risk of data breaches and unauthorized access that can occur with cloud-based services.
- Customization: Local deployment allows you to tailor the LLM to your specific needs. You can fine-tune the model parameters, training data, and features to better align with your organization's specific requirements, ensuring more relevant and efficient outputs.
- Data Integration: With a local LLM, you have the flexibility to integrate a wide range of internal documents, policies, and data sources directly into the AI model. This integration allows for more nuanced and contextually aware responses, making the LLM more useful in addressing organization-specific queries or tasks.
- Security: Local hosting provides a more secure environment for your data. By keeping your LLM in-house, you're not only controlling physical access to your data but also minimizing exposure to external threats. This is especially important for sectors where data security and compliance with regulations like GDPR or HIPAA are paramount.
Things to consider:
- Resource Demand: Prepare for substantial computational requirements as running LLMs is a GPU-intensive task. A dedicated machine with a high-end GPU is ideal for this.
- Open Source vs. Cutting-Edge: Open-source LLMs may not be the most cutting-edge models, but they're robust for a wide range of tasks.
- Limited Scalability: As your needs grow, scaling a locally hosted LLM can be more challenging and expensive compared to cloud-based solutions.
Components:
- Ollama: Ollama is an open-source framework that facilitates the local deployment of large language models like Llama 2 on your own infrastructure. Ollama.ai is compatible with various open-source language models and integrates with platforms like MindsDB. This enables a range of AI tasks while ensuring data privacy and reducing latency. Its user-friendly approach allows Linux enthusiasts to leverage their hardware for efficient AI model operation. Ollama stands out for its command-line interface, making it accessible and practical for a wide range of AI-driven applications.
- Ollama can be run on every major platform, including Linux, Windows and macOS.
- Open WebUI: OpenWebUI is a comprehensive WebUI that operates offline and supports various Large Language Model (LLM) runners, including Ollama and OpenAI-compatible APIs. It is designed to be extensible, feature-rich, and user-friendly.
- Open WebUI serves as the frontend for Ollama, facilitating the conversation between the user and Ollama's API using a GPT-like web interface.
- Large Language Models: Large Language Models (LLMs) are advanced AI models designed to process, understand, and generate human-like text. They are "large" not just in terms of their physical size (involving substantial computing resources) but also in the scope of their training data. These models are trained on diverse and extensive datasets comprising books, articles, websites, and other forms of text, enabling them to understand and respond to a wide range of queries and prompts. This training allows them to perform a variety of tasks, including translation, summarization, question answering, and creative writing, among others.
- This guide uses pre-trained LLMs and is not focused on training models as training models are extremely resource intensive tasks, requiring unfathomable amounts of computing resources and data sets. This guide focuses on using pre-trained AI models and having them reference internal documentation and knowledge. This is not the same as re-training the model, but rather involves fine-tuning or adapting them to specific tasks or datasets using techniques like transfer learning or prompt engineering, thereby leveraging their vast pre-existing knowledge while tailoring their responses to specific needs or contexts.
The Backend
Before installing Ollama, it is recommended to have a GPU with CUDA installed on your machine. To download Ollama, navigate to Ollama and Download the installer.
The installer will walk you through all steps. After installation, the Ollama API will be reachable from
The Frontend
Docker is required for installing Open WebUI.
- Run the installation command in CMD to install.
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
- Navigate to
:3000, or add it to your reverse proxy to be able to access it under chat.mydomain.com. - Sign up for a new account. The first account created after Open WebUI is installed is the administrator account.
Models
Ollama and Open WebUI are now installed, the next step is to download LLMs.
- To view available models, navigate to Ollama's Model Libary and select a model.
- Copy the name of the model (eg.: mistral) and navigate back to the Open WebUI portal.
- Click Settings > Models> Pull a model and paste in the name of the model to download it.
Interacting with your AI:
Always check for the latest available features. This is accurate at the time of writing this post:
- Browse websites: Specify websites with #{URL} to add web content to the conversation.
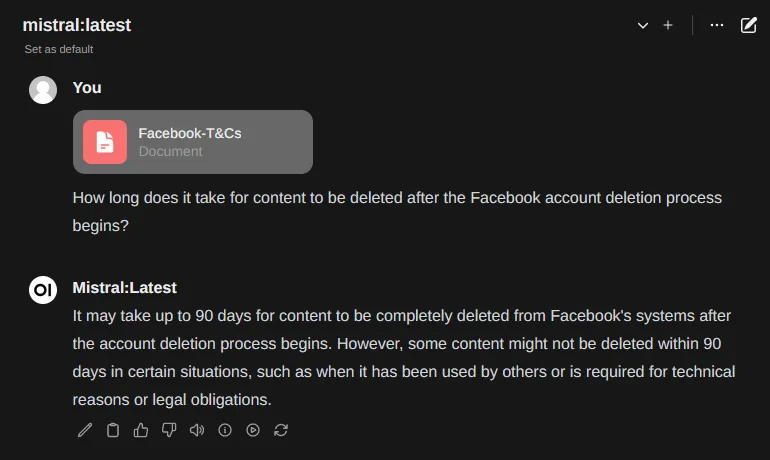
- Link documents: Drag and drop documents directly into the chat window to talk about them while the chat is open.
- Define Document Base: Upload documents to store within Open WebUI and reference at any time with #{Document Name} by uploading them under Documents > Add Docs
- Create your own Modelfile: Define how your model should interact with you and create models for specific purposes under Modelfiles > Create a modelfile.
- Use multiple models in the same conversation: At any time, swap LLMs during conversation. Especially useful when the topic of the conversation changes and you have more powerful LLMs available to complete the task (for example wizard-math). You can also use collaborative chat with @{Model Name} to orchestrate group conversations.
Conclusion:
Deploying a locally-hosted Large Language Model offers a unique blend of security, customization, and direct control over sensitive data, making it an increasingly attractive option for small and midsize businesses and homelab enthusiasts. While there are challenges, such as the need for substantial computational resources and potential scalability issues, the benefits of confidentiality, tailored AI responses, and robust data integration are compelling. By leveraging open-source tools like Ollama and Open WebUI, businesses can harness the power of LLMs in a way that aligns with their specific needs and security requirements. As AI continues to evolve, the potential for localized LLM deployment is vast, promising even more control, efficiency, and customization in the near future. This guide serves as a starting point for those ready to embark on the journey of deploying these powerful models within their own infrastructure.