TL;DR: This post covers two ways of adding AI vision to Home Assistant; first with a proxy that pipes snapshots through Ollama, and then with Frigate 16’s new built-in GenAI and face recognition. I also show how to use Home Assistant’s new AI Task to make it task-driven and voice-enabled.
Last year on I wrote a guide on setting up Frigate with Home Assistant to create a privacy-friendly local CCTV system. That setup handled recognition well, but it had way too many components (Frigate, Double-Take, DeepStack).
This time I wanted to push it further. The idea was to have the CCTV actually describe what it sees in real time, and to do it entirely on my own hardware. No cloud services, no footage sent away to third parties, just Frigate, Ollama, and Home Assistant all talking to each other.
When I started building this, Frigate 0.16 wasn't out yet. I moved away from the original Frigate/Double-Take/DeepStack setup and I put together a custom proxy that Home Assistant could call, which in turn sent images to Ollama and got a description back. Later, when 0.16 beta landed, I found that Frigate had grown facial recognition and a Generative AI integration. At that point I could throw away my proxy and just let Frigate handle the whole thing. Much cleaner, fewer moving parts.
Then, in August, Home Assistant's latest release included an Ollama integration update; they added AI Task, essentially services that can be leveraged to handle various tasks where simple automations just won't work, allowing you to connect a vision model directly to the live CCTV feeds, essentially skipping Frigate's recognition model altogether.
So, here are all three methods. If you're on an older Frigate or want to micro-manage the prompts from inside Home Assistant, the DIY proxy works. If you're running Frigate 16 or newer, use the built-in GenAI. And finally, since Home Assistant added AI Task in the August update, I’ll show how I tied the whole lot into a voice routine.
What can this be used for?
A setup like this adds real intelligence to your home. Some examples:
- Message you if an unfamiliar car parks outside your house and stays longer than 5 minutes.
- Your house recognizes a stranger lingering by the gate and politely asks if they need help.
- Ask Home Assistant "Who’s at the gate?" and have it reply with a live description, including names and whether they are family, friends or strangers.
- For visually impaired users, voice queries like "What’s happening in the backyard?" could return a live description ("Two people are sitting by the patio table with drinks").
- Detect if someone is carrying a package towards your door and and trigger a delivery routine even before they reach the doorbell. Similarly, your home "knows" you arrived with grocery bags and automatically unlocks the door and turns on the hallway lights.
- Count how many people are in the living room and adjust the thermostat or ventilation accordingly.
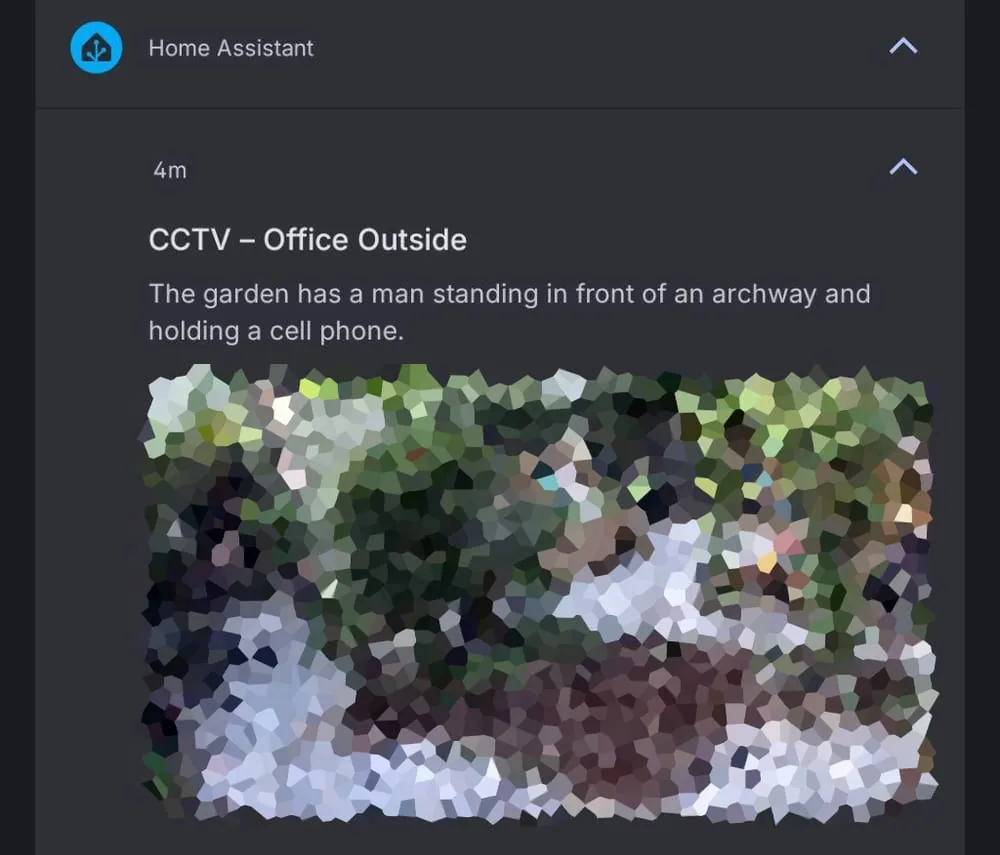
Vision - Method 1 — Custom Ollama Proxy
This method is good if you're still on Frigate < 0.16, or if you like keeping all the prompt logic on the Home Assistant side. I originally built this to run to ditch Double Take for facial recognition.
How it works is straightforward:
- Home Assistant detects a person via Frigate.
- HA sends the snapshot URL to a small containerised FastAPI proxy.
- The proxy fetches the image, encodes it in Base64, and passes it to Ollama.
- Ollama runs a vision model locally and returns a short description.
- HA includes the description and the image in a mobile notification.
Step 1 — Proxy
A minimal FastAPI app in Docker.
# app.py
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import requests, base64
OLLAMA_URL = "http://OLLAMA-HOST:11434/api/generate" # Ollama endpoint
app = FastAPI()
class DescribeIn(BaseModel):
image_url: str
model: str = "gemma3:4b"
prompt: str = ("Describe the person succinctly: clothing, approx age, "
"accessories, action. One short sentence.")
stream: bool = False
timeout: int = 20
@app.post("/describe")
def describe(body: DescribeIn):
try:
r = requests.get(body.image_url, timeout=max(5, body.timeout // 2))
r.raise_for_status()
img_b64 = base64.b64encode(r.content).decode("utf-8")
payload = {
"model": body.model,
"prompt": body.prompt,
"images": [img_b64],
"stream": body.stream
}
resp = requests.post(OLLAMA_URL, json=payload, timeout=body.timeout)
resp.raise_for_status()
j = resp.json()
text = (j.get("response") or "").strip()
return {"response": text or "No description returned by model."}
except requests.exceptions.RequestException as e:
raise HTTPException(status_code=502, detail=f"Ollama/proxy HTTP error: {e}")
except Exception as e:
raise HTTPException(status_code=500, detail=f"Proxy error: {e}")
Dependencies:
# requirements.txt
fastapi
uvicorn
requests
And the Dockerfile:
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY app.py .
EXPOSE 5005
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "5005"]
Build and run it:
docker build -t ollama-proxy .
docker run -d --name ollama-proxy -p 5005:5005 --restart unless-stopped ollama-proxy
Test with curl:
curl -s -X POST http://PROXY-IP:5005/describe \
-H 'Content-Type: application/json' \
-d '{"image_url":"https://images.pexels.com/photos/220453/pexels-photo-220453.jpeg"}'
You should get something like:
{"response":"A man wearing a black shirt looks at the camera."}
Step 2 — Home Assistant integration
configuration.yaml:
rest_command:
describe_person:
url: "http://PROXY-IP:5005/describe"
method: POST
content_type: "application/json"
timeout: 25
payload: >-
{
"image_url": "{{ image_url }}",
"model": "gemma3:4b",
"prompt": "Describe the person succinctly: clothing, approx age, accessories, action. One short sentence.",
"stream": false
}
Restart HA.
Step 3 — HA Automation
When a person is detected:
alias: Alarm - CCTV Unknown Person (REST Ollama via Proxy)
mode: parallel
trigger:
- entity_id: sensor.double_take_unknown
platform: state
action:
- variables:
filename: "{{ trigger.to_state.attributes.unknown.filename | default('') }}"
token: "{{ trigger.to_state.attributes.token | default('') }}"
person_image_url: >-
{% set base = 'http://PROXY-IP:3010/api/storage/matches/' %}
{% if filename %}
{{ base ~ filename ~ '?box=true' ~ ( '&token=' ~ (token | urlencode) if token else '' ) }}
{% else %}
''
{% endif %}
- data:
image_url: "{{ person_image_url }}"
response_variable: ollama
action: rest_command.describe_person
- variables:
raw: "{{ ollama | default({}) }}"
ai_msg: >-
{% set raw_str = raw | tojson if raw is mapping else (raw | string) %}
{% set m_json = raw_str | regex_findall('"response"\\s*:\\s*"([^"]*)"') %}
{% set m_py = raw_str | regex_findall("\\'response\\'\\s*:\\s*\\'(.*?)\\'") %}
{% set text = (m_json[0] if m_json else (m_py[0] if m_py else '')) %}
{{ text | replace('\n',' ') | regex_replace('\\s+',' ') | trim | capitalize | regex_replace('[.!?]+$','.') | default('Person detected while the alarm system is armed.', true) }}
- service: notify.mobile_app
data:
title: CCTV
message: "{{ ai_msg }}"
data:
image: "{{ person_image_url }}"
Vision - Method 2 — Frigate 16 with GenAI
From 0.16 onwards, Frigate gained facial recognition and GenAI integration. This means you can drop Double Take and the proxy. Frigate itself can recognise faces, send frames to Ollama (or OpenAI, if you wanted), and publish the description over MQTT.
Step 1: Enable face recognition in your Frigate config:
face_recognition:
enabled: true
Train faces directly in the Frigate UI. You do not need to pre-train the model. When a person is detected, Frigate will save the snapshots, which can then be selected and assigned to a person. Pre-training helps with proactive recognition though.
Step 2: Enable GenAI with Ollama in your Frigate config:
semantic_search:
enabled: true
genai:
enabled: true
provider: ollama
base_url: http://OLLAMA-IP:11434
model: llava:7b
prompt: "Describe the person succinctly: clothing, approx age, accessories, action. One short sentence."
cameras:
front_door:
genai:
enabled: true
objects: [person]
Frigate supports template variables like {camera} and {sub_label}, so if a recognised face is matched, you can pass the name into the prompt.
Step 3 — Home Assistant automation via MQTT:
alias: Alarm - CCTV Person (Frigate GenAI)
mode: parallel
trigger:
- platform: mqtt
topic: frigate/tracked_object_update
value_template: "{{ value_json.type }}"
payload: "description"
variables:
event_id: "{{ trigger.payload_json.id }}"
ai_msg: "{{ trigger.payload_json.description | default('Person detected.') }}"
img_url: "http://FRIGATE-IP:5000/api/events/{{ event_id }}/snapshot.jpg?bbox=1"
action:
- service: notify.mobile_app
data:
title: CCTV
message: "{{ ai_msg }}"
data:
image: "{{ img_url }}"
That’s it. Much simpler.
The only downside of this setup, compared to the HA + Proxy route, is that Frigate doesn’t natively support schedules or conditions for when detections are passed to the LLM for description. For example, I’d prefer to only generate descriptions when I'm not home. While you can of course handle the notification logic inside Home Assistant automations, Frigate will still run the descriptions in the background regardless, meaning your GPU is burning cycles on results you'll never use.
So which should you use?
If you’re already on Frigate 16, just use the GenAI integration. It's built in, has face recognition, and makes everything cleaner. If you’re on an older release, or you like writing your own prompts in HA, the proxy method still works and gives you more control as you can specify the exact pipeline you are building.
Home Assistant AI Task
In August, Home Assistant rolled out AI Task with Ollama. You can now run not just conversational agents, but also automations that pass speicifc tasks to Ollama and get structured JSON back.
You could push image recognition through it, but I'll still keep Frigate’s face recognition for regular CCTV tasks, as it has face libraries and training built in, which HA doesn't. The AI Task can shine in other aspects in terms of vision, like the highly-specific task of counting objects as shown on the example page. Instead, I used AI Task for a voice routine.
The idea is simple: the first time I walk into my office in the morning, HA greets me, tells me the weather (inside and outdoors), highlights a few tech news headlines, and reads me my next calendar event. For voice, I'm using ElevenLabs for nicer quality in this example, but my other AI Task automations use Coqui TTS.
Helper
As I'm tracking the first time I walk into the office, the automation will need to be able to compare the current time against the last time the presence/motion sensor detected motion. To do this, I created a helper that records the last activity in configuration.yaml:
input_datetime:
last_office_entry:
name: Last Office Entry
has_date: true
has_time: false
Reload helpers / restart HA.
Automation
alias: AI Morning Routine (first office entry 06:00–20:00)
description: Generates a daily greeting using an AI Task on first office entry after 06:00.
triggers:
- entity_id:
- binary_sensor.office_motion_sensor_occupancy
to: "on"
trigger: state
conditions:
- condition: time
after: "06:00:00"
before: "20:00:00"
- condition: template
value_template: >
{{ states('input_datetime.last_office_entry') !=
now().strftime('%Y-%m-%d') }}
actions:
- target:
entity_id: input_datetime.last_office_entry
data:
date: "{{ now().strftime('%Y-%m-%d') }}"
action: input_datetime.set_datetime
- data:
task_name: greeting
instructions: >-
Given the current hour in 24-hour format, generate a friendly,
context-appropriate, creative greeting for <Name> in the office. Respond
only with the greeting—no explanations, no pretext.
entity_id: ai_task.ollama_ai_task
response_variable: greeting
action: ai_task.generate_data
- data:
task_name: weather report
instructions: >+
Tell me what the weather is, jokingly. Keep it to maximum 2 sentences,
no pretext, straight to the weather report, mentioning the temperature
and humidity:
- Outdoor temperature: {{ states('sensor.openweathermap_temperature')
}}°C
- Weather condition: {{ states('weather.openweathermap') }}
- Office temperature: {{
states('sensor.office_temperature_and_humidity_temperature') }}°C
- Office humidity: {{
states('sensor.office_temperature_and_humidity_humidity') }}%
structure:
weather_description:
description: Short description of the outdoor weather and temperature
required: true
selector:
text: null
entity_id: ai_task.ollama_ai_task
response_variable: comfort_report
action: ai_task.generate_data
- data:
task_name: tech news
instructions: >-
From the list of news headlines below, select the three most important ones for <User>. Focus on wide impact and cybersecurity, privacy and important news. Use each headline only once. Write the result as two short, natural sentences, using only the article titles. Do not add explanations or prefaces.
Headlines:
{% for e in state_attr('sensor.bleepingcomputer', 'entries') or [] -%}
- {{ e.title }}
{% endfor %}
{% for e in state_attr('sensor.arstechnica', 'entries') or [] -%}
- {{ e.title }}
{% endfor %}
structure:
news:
required: true
selector:
text: null
entity_id: ai_task.ollama_ai_task
response_variable: tech_news
action: ai_task.generate_data
enabled: true
- data:
task_name: calendar
structure:
calendar:
required: true
selector:
text: null
entity_id: ai_task.ollama_ai_task
instructions: >-
Summarize the next calendar event for today in a short, natural-sounding sentence. Use the event title and the start time. Do not add explanations or prefaces.
Calendar entries:
{% set cal = states.calendar.user_work_calendar %}
{% if cal.attributes.start_time is defined %}
- {{ cal.attributes.message }} at {{ cal.attributes.start_time }}
{% else %}
- No events
{% endif %}
response_variable: calendar
action: ai_task.generate_data
enabled: true
- action: tts.clear_cache
metadata: {}
data: {}
- action: tts.speak
metadata: {}
data:
cache: false
media_player_entity_id: media_player.home_assistant_voice_media_player
message: |
{{ greeting.data }}
{{ comfort_report.data.weather_description
| replace("°C", " degrees")
| replace("%", " percent") }}
Now to the news headlines:
{{ tech_news.data.news
| regex_replace(', (?=[A-Z])', '. ')
| regex_replace('[^a-zA-Z0-9 .!?]', '')
| regex_replace('\s+', ' ')
| trim }}
Your next meeting is: {{ calendar.data.calendar }}
enabled: true
target:
entity_id: tts.elevenlabs
mode: single
Feedparser is used for the RSS news. MS365-Calendar is used for the calendar integration.
So that's where things are now: from simple person detection last year, to actual descriptions this year, and now a smart voice routine layered on top. All local, no cloud, and honestly, a lot more fun to walk into the office in the morning.
This shift opens the door to a new generation of smart homes. Ones that are not only private and local-first, but also conversational, adaptive, and genuinely helpful. It's time for LLMs to make Home Assistant human-friendly.